
















总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼
别让工厂老师傅的经验退休:我们把它“喂”给了AI
石油化工的生产线上,没有一句废话。 每一条跳动的曲线,都是设备在诉说自己的状态; 每一个数字的波动,都是工艺在传递运行的密码。 |
走进任何一座石化厂的控制室,你都会看到满墙的屏幕上,无数条五颜六色的曲线在不停跳动。温度、压力、流量、液位……这些每秒都在刷新的数字,构成了石油化工行业独有的"语言"。
对于在一线工作了30年的老工程师来说,这些曲线就像老朋友的声音一样亲切。看一眼曲线的走势,他就能立刻知道反应器里的反应是否正常,换热器有没有结垢,泵体是否出现了异常。
但对于人工智能来说,这些曲线只是一堆毫无意义的数字。
它能看到温度从280℃升到了285℃,却不知道这5℃的上升意味着什么;它能记录压力的波动,却读不懂波动背后隐藏的故障风险;它能计算出所有参数的变化趋势,却无法说出"为什么会这样"以及"接下来该怎么办"。
这就是当前工业智能化面临的最大鸿沟:机器能看见工业的数据,却听不懂工业的语言。
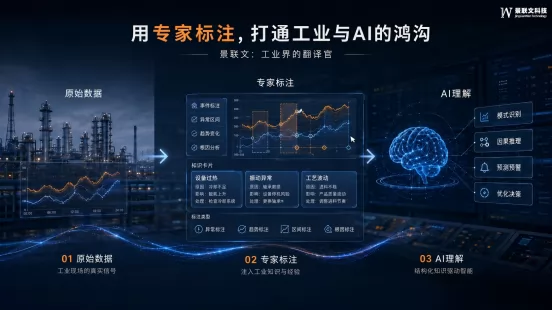
而景联文科技正在做的事情,就是成为工业界的"翻译官"——用专家级工业时序数据标注,搭建起工业知识与人工智能之间的桥梁。
石油化工的"语言",到底有多难学?
很多人对数据标注的印象还停留在 "拉框打字",觉得不就是给数据打标签吗?但如果你真的了解石油化工,就会知道想把石化专家阅读复杂工控曲线的思考逻辑,并用文字把思考、分析和经验记录下来,是一门门槛极高的专业活。
石油化工是典型的流程工业:生产系统高度耦合、连续不间断运行,上万个传感器实时采集的数据不是孤立的点,而是一张精密的因果网络。同一个参数的微小波动,在不同工艺、不同工况、不同设备上,可能代表着完全相反的含义。
举个最常见的例子:
当反应器床层温度在 10 分钟内上升 5℃时,普通人看到的只是一个数字变化。 但在石化专家眼里,这背后可能对应着十几种完全不同的成因:原料性质波动、催化剂活性变化、再生系统异常、仪表测量误差、进料量调整滞后…… 每一种成因对应的处置方案天差地别,判断失误轻则影响产品收率,重则引发安全事故。 |
这就是石化语言的独特之处,也是普通数据标注无法胜任的根本原因:
• 没有通用字典:绝大多数工艺知识是老专家几十年现场经验的沉淀,从未被系统化、数字化记录
• 强语境依赖:同一个数据信号,在开停车、正常运行、故障处置等不同工况下语义完全不同
• 因果关系复杂:一个现象可能由多个诱因叠加导致,一个参数变化会引发全流程的连锁反应
• 零容错要求:标注错误的代价是生产安全和巨额经济损失,远非普通标注的 "准确率" 可以衡量
• 系统复杂度极高:每个石化工艺的主要设备控制位点动辄上万个,人类注意力有限,极难从海量特征中定位问题相关特征子集
这也解释了为什么行业里会出现单条标注千元的现象 ——工业数据标注标注的从来不是数据本身,而是数据背后的工业知识和专家经验。
机器的 "语言障碍",本质是数据标注的痛点
结合我们服务客户的经验来看,工业大模型的痛点,本质上是高质量专家标注数据的缺失:
1. 生成内容深度浅:只能复述通用教科书知识,无法理解具体工艺的参数逻辑和操作细节
2. 模型幻觉严重:面对专业问题经常编造答案,给出的建议完全不符合生产实际
3. 指令遵循能力差:无法准确理解复杂的工业生产指令,输出结果与现场需求脱节
4. 应用安全无保障:缺乏可解释性,无法说明决策依据,工程师根本不敢用于生产控制
工业领域的核心知识,是老专家的经验,写在泛黄的笔记本里,藏在每次微调参数的动作里,体现在对异常曲线的直觉判断里。这些知识没有被标注成 AI 能够理解的格式,大模型自然学不会工业的 "语言"。
更重要的是,目前大模型只能学习数据的统计规律,无法理解数据背后的物理机理和因果关系。
这就是为什么很多工业大模型看起来很美好,一到现场就"水土不服":
• 它能告诉你"设备可能会故障",但说不出"为什么会故障" • 它能给出一堆参数建议,但无法解释"为什么要这么调" • 它的预测结果时好时坏,没有任何规律可循,工程师根本不敢用 |
某石化厂的总工曾经跟我们说过一句很扎心的话:"一个说不出理由的AI建议,和瞎猜有什么区别?我总不能拿着全厂的安全生产去赌它猜得对不对吧?"
这就是工业大模型的"阿喀琉斯之踵":不可解释的AI,永远无法进入工业生产的核心环节。
而要解决这个问题,唯一的办法是:让真正懂工业语言的人,来教AI说话。
这就是景联文存在的价值:作为专业的数据标注服务商,我们把分散在无数专家脑子里的隐性知识,转化为 AI 能够学习的显性数据。
景联文用专业数据标注打通工业与 AI 的鸿沟
景联文科技是国内最早布局工业数据标注的专业数据服务商之一,我们的核心资产不是标注员,而是行业专家库和经过验证的工业数据标注体系。
1. 最专业的 "翻译团队",汇聚工业领域的 "母语者"
要做好工业翻译,首先得懂工业语言。我们通过QApex 专家数据资源运营平台,汇聚了来自石油化工等流程工业领域的数千名资深专家,有石油大学的教授和博士,全身心投入在核心工艺的研究和设计上,还有资深工程师和设备运维专家等。同时建立严格的专家准入、分级和考核机制,只有具备多年现场经验、掌握核心工艺知识的专家,才能参与工业数据标注项目。
2. 最智能的 "翻译工作台",双平台赋能高效标注
好的翻译官需要好的工具。我们自研的SolarSense智能多模态数据工程平台,支持 DCS、MES等工业系统的数据接入,统一处理多源异构数据,数据智能体可以对数据集进行详细分析,识别数据集中的潜在风险,给出加工和使用建议,并通过平台承载的定制化工业时序标注工具体系,完成数据预处理、标注加工、透视分析、导出等操作。
QApex 平台则负责专家资源的精准匹配、任务分发、进度管控和质量验收,实现了 "需求 - 标注 - 审核 - 交付" 的全流程线上化管理,让专家可以专注于最核心的知识翻译工作。
3. 最科学的 "翻译方法",四位一体标注范式
我们创建"场景来源 + 过程机理 + 行业数据 + 模型验证" 四位一体的工业数据标注范式,不同于普通标注只在曲线上标一个 "异常点",我们的工业时序数据标注要求专家对每一个时序事件进行完整的语义翻译,包含四个核心维度:
1. 现象描述:准确记录数据变化的时间、范围和特征
2. 机理解释:说明数据变化背后的物理化学原理和工艺逻辑
3. 影响分析:分析该事件对上下游工序和产品质量的影响
4. 处置建议:给出符合现场实际的标准化操作指导
这种 "时序数据 + 自然语言描述" 的交叉嵌入标注法,将专家的隐性知识转化为了 AI 能够理解的结构化数据,从根本上解决了工业大模型的可解释性问题。
通过这套专业的工业数据标注体系,我们已经帮助多家行业头部企业完成了核心工艺的知识数字化。
有人问我们:做这件事的意义是什么?
我们的回答是:我们正在为工业文明打造一个"数字大脑"。

过去一百年,石油化工行业的进步,靠的是一代又一代工程师的经验积累。这些经验是工业文明最宝贵的财富,但它们也是脆弱的——它们依附于人的大脑,会随着人的离开而消失。
而今天,我们正在做的事情,就是把这些分散在无数人脑子里的经验,汇聚成一个数字化的知识宝库,让它们能够被永久保存、被广泛分享、被不断迭代。
未来,当AI真正听懂了工业的语言,它将成为每一个工程师的得力助手。它不会取代人类,但它会让人类的经验发挥出更大的价值,它会让生产更安全、更高效、更环保。
而我们,将继续做好工业界的 "翻译官",用专业的工业数据标注,为中国工业的智能化转型筑牢数据底座。





总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼
北京分公司
北京市海淀区光耀东方广场1幢9层902室
重庆基地
重庆市两江新区卉竹路2号互联网产业园2期11号楼5楼
贵阳基地
贵州省贵阳市云岩区中建大厦36楼

微信公众号

客户咨询微信
CopyRight ©️ 2026 杭州景联文科技有限公司 All Right Reserved.