













Headquarters Address
Hangzhou Xiaoshan District Hangzhou Bay Information Port Building E, 7th Floor


As the core engine of artificial intelligence, unleashing the infinite potential of AI with every piece of data.

Free Consultation for Customers

We provide full-chain services from data infrastructure construction to data operations
Forming a data flywheel to empower a virtuous cycle in the industry
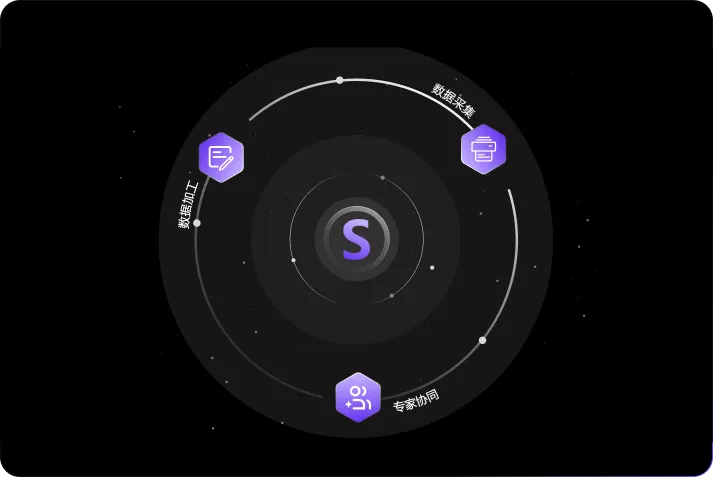
Data Collection and Annotation

Providing automated/manual data collection capabilities for multiple scenarios, covering full-modal data sources such as text, images, audio, and video. Based on an intelligent corpus engineering platform, it enables end-to-end data processing, including cleaning, annotation, enhancement, quality inspection, and other stages, outputting high-quality structured training corpora.
Providing automated/manual data collection capabilities for multiple scenarios, covering full-modal data sources such as text, images, audio, and video. Based on an intelligent corpus engineering platform, it enables end-to-end data processing, including cleaning, annotation, enhancement, quality inspection, and other stages, outputting high-quality structured training corpora.
AI Dataset
Based on the accumulation of massive data and industry insights, we provide standardized, high-quality, ready-to-use AI training datasets. Our products are derived from real business scenarios, professionally collected and accurately annotated.
Based on the accumulation of massive data and industry insights, we provide standardized, high-quality, ready-to-use AI training datasets. Our products are derived from real business scenarios, professionally collected and accurately annotated.
SolarSense Language Data Engineering Platform
The SolarSense Language Data Engineering Platform is designed for the full lifecycle management and operational scenarios of multi-source heterogeneous data. It constructs a comprehensive language data engineering system covering the entire workflow from data collection, governance, annotation, quality inspection, enhancement, to catalog operation and maintenance. The platform is dedicated to addressing core challenges in fields such as government affairs, healthcare, education, and financial intelligence during the process of data assetization, including issues like inconsistent standards, uncontrollable quality, and difficulties in value transformation.
The SolarSense Language Data Engineering Platform is designed for the full lifecycle management and operational scenarios of multi-source heterogeneous data. It constructs a comprehensive language data engineering system covering the entire workflow from data collection, governance, annotation, quality inspection, enhancement, to catalog operation and maintenance. The platform is dedicated to addressing core challenges in fields such as government affairs, healthcare, education, and financial intelligence during the process of data assetization, including issues like inconsistent standards, uncontrollable quality, and difficulties in value transformation.
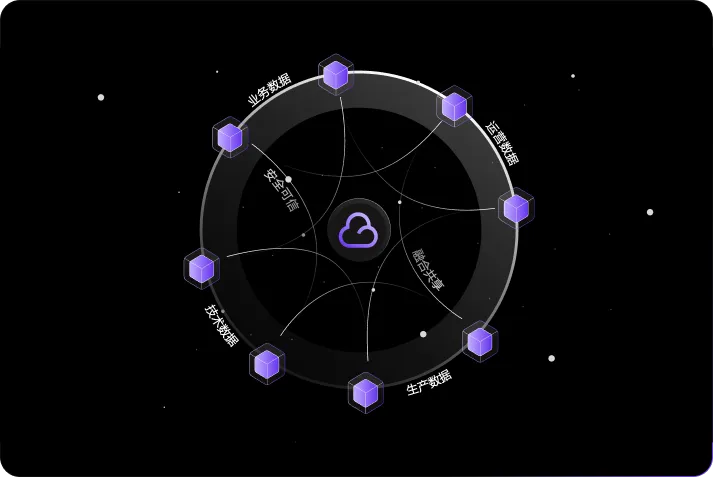
Credible Data Space
Jinglianwen Technology possesses petabyte-scale large model data, covering question banks, multimodal content, text, images, videos, audio, and all data types, while also providing large model data annotation services.
Jinglianwen Technology possesses petabyte-scale large model data, covering question banks, multimodal content, text, images, videos, audio, and all data types, while also providing large model data annotation services.
Provide full-process public data and enterprise data operation
solutions for 'data-scenario-application'
Head Data Production and Operations Provider,
Driving the Intelligent Cycle of Industry, Your Full-Path Data Partner


Industry Standard Leader
2
Project Leadership13
Item Participation
Number of Service Customers
1000
+

Honor & Qualifications
120
+



Media Attention

Customer Advantage
80
%

Authority Recognition

Airi Consulting Data Service Representative Manufacturer
IDC Data Service Representative Manufacturers
Representative Manufacturers of MIIT Data Services
Representative Manufacturers of Billion Euro Intelligent Database Data Services
About Us

Jinglianwen Branch 1000+ customer structure already covers government, domestic mainstream large model companies, leading AI manufacturers, AI research institutions










































Jinlianwen
Jinlianwen





Headquarters Address
Hangzhou Xiaoshan District Hangzhou Bay Information Port Building E, 7th Floor
Beijing Branch Company
Room 902, Unit 29, Building 1, Guangyao Dongfang Plaza, Haidian District, Beijing
Chongqing Base
No. 2, Huizhu Road, Liangjiang New Area, Chongqing 5th Floor, Building 11, Phase 2, Internet Industrial Park
Guiyang Base
36th Floor, Zhongjian Building, Yunyan District, Guiyang City, Guizhou Province

WeChat Public Account

Customer Consultation WeChat
Copyright © 2026 Hangzhou Jinglianwen Technology Co., Ltd. All Rights Reserved.