

















总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼
从"体力活"到"脑力活":数据标注行业的第三次革命已经到来
当所有人都在谈论大模型如何改变世界时,很少有人注意到,正在改变大模型本身的,是一场悄无声息发生在数据标注行业的革命。 |
很多人对数据标注的印象,还停留在"拉框打字、日结工资"的流水线工厂。在他们看来,这是一份没有技术含量的体力活,只要会用电脑就能做。
但今天,这个认知已经彻底过时了。
就在刚刚过去的 2026 年第一季度,国内工业数据标注市场,一条包含完整工艺机理、因果链条和处置建议的石化专家标注,价格是普通文本标注的 1000 倍以上。即便如此,能看懂 DCS 系统曲线、理解催化重整、催化裂化、加氢裂化、渣油加氢、延迟焦化、汽柴油加氢等石化核心工艺的资深工程师依然一师难求 —— 截至2025年末,国内工业领域复合型AI数据专家缺口已达33万人次,而全行业具备工业时序数据标注能力的专业团队极其稀少。
这一切的背后,是数据标注行业正在经历的第三次革命——从"人力密集型"到"技术密集型",再到今天的"知识密集型"。这场革命不仅正在重塑整个行业的格局,更将决定未来十年人工智能的发展高度。
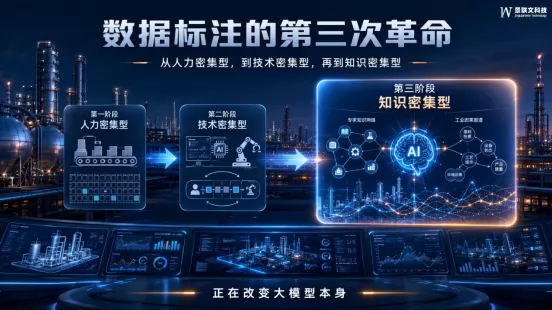
第一次革命(2012-2018):拼人头的"数据工厂"时代
2012年,AlexNet在ImageNet竞赛中一战成名,拉开了深度学习时代的序幕。随之而来的,是对海量标注数据的爆发式需求。
这是数据标注行业的第一次革命,也是最广为人知的一个阶段。
核心特征:人力密集型,规模为王
• 标注内容:以图片分类、目标检测、语音转写、文本分词等通用基础标注为主
• 生产模式:大规模标注基地,"流水线"式作业,一个标注员一天可以完成上千张图片的标注
• 竞争逻辑:拼价格、拼人头、拼交付速度,谁的成本低谁就能拿到订单
那个时候,全国涌现出了上千家数据标注公司,很多公司的核心竞争力就是"能拉到多少人"。在一些三四线城市,标注基地甚至成为了当地的重要就业渠道,一个标注员月薪3000-5000元,标注一张图片的价格只有几分钱。
但这种模式的弊端很快就显现出来了:同质化严重,价格战愈演愈烈,行业平均利润率不足10%。很多公司为了生存,不得不牺牲质量换取低价,导致大量低质量数据流入市场,最终拖慢了AI模型的迭代速度。
行业反思:第一次革命解决了"有没有数据"的问题,但没有解决"数据好不好"的问题。当通用AI发展到一定阶段,单纯靠堆人头已经无法满足行业的需求了。 |

第二次革命(2018-2023):技术赋能的"人机协同"时代
2018年之后,随着AI技术本身的进步,数据标注行业迎来了第二次革命。
核心特征:技术密集型,效率为王
• 标注内容:从通用基础标注向多模态标注、3D点云标注等复杂标注延伸
• 生产模式:"AI预标注+人工修正"的人机协同模式,AI完成70%-80%的基础工作,人只需要做最后的校验和修正
• 竞争逻辑:拼技术、拼工具、拼平台能力,谁的标注效率高谁就能胜出
在这个阶段,一批有技术实力的公司开始脱颖而出。他们开发了自己的标注平台,引入了预标注、自动质检、批量处理等技术,将标注效率提升了3-5倍。比如,原来一个标注员一天只能标注100张3D点云图,有了AI预标注之后,一天可以标注300-400张。
景联文科技正是在这个阶段完成了第一次技术升级。我们打造了SolarSense多模态AI数据智能加工底座,集成了文本、视频、音频、图像等全模态标注工具,实现了数据清洗、脱敏、标注、质检的全流程自动化。
但第二次革命依然有其局限性:
• AI只能处理标准化、重复性的标注任务,无法理解数据背后的深层逻辑
• 对于需要专业知识的行业数据,AI预标注的准确率甚至不足30%
• 行业依然没有摆脱"人力外包"的本质,只是从"纯人力"变成了"技术+人力"
行业判断:技术可以提升通用数据的标注效率,但永远无法替代人类的专业知识。当大模型开始向行业深入,数据标注行业需要一场更彻底的变革。 |

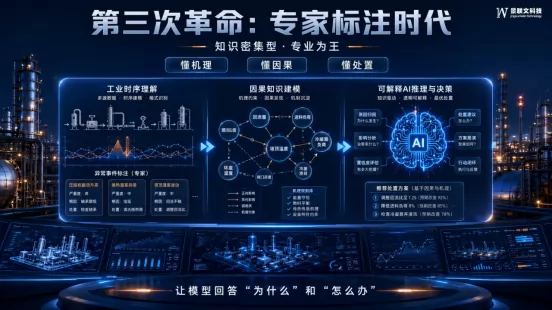
第三次革命(2023-至今):知识驱动的"专家标注"时代
2023年,ChatGPT横空出世,通用大模型的能力得到了质的飞跃。但与此同时,行业也发现了一个残酷的现实:互联网公开数据已经被大模型基本训练完毕了。
当前,通用基座模型的能力已经完全溢出,赋能行业场景正当其时。
未来,大模型的竞争将不再是参数的竞争,而是行业数据的竞争。谁能掌握高质量的行业数据,谁就能在垂直领域大模型的竞赛中占据先机。
这就是数据标注行业的第三次革命——从"技术密集型"向"知识密集型"的跨越。
核心特征:知识密集型,专业为王
• 标注内容:从通用数据转向行业数据,需要标注的不再是"是什么",而是"为什么"和"怎么办"
• 生产模式:"专家+平台"的协同模式,行业专家成为标注的核心,技术平台成为支撑专家高效工作的工具
• 竞争逻辑:拼专家资源、拼行业理解、拼标准制定能力,谁能将专家经验数字化,谁就能掌握行业的核心竞争力
这是一场彻底的范式革命。过去,数据标注员只需要会用电脑;现在,数据标注员需要是石油化工工程师、医生、律师、教师等各个领域的专家。过去,标注的价格是按"条"或"张"计算;现在,标注的价格是按"知识含量"计算,一条包含完整因果链条的专家标注,价格可以达到普通标注的1000倍以上。
"第一次革命拼人头,第二次革命拼技术,第三次革命拼知识。未来的数据标注公司,本质上是知识服务公司。景联文科技的核心资产不是多少个标注员,而是多少个行业专家,以及我们将专家经验转化为AI可理解数据的能力。" |
景联文科技:第三次革命的引领者与定义者
当大多数行业玩家还在第二次革命的赛道上拼技术时,景联文科技已经率先完成了向知识密集型标注的转型,成为了第三次革命的引领者。
我们的核心武器,是"双平台驱动+专家生态"的创新模式:
1. SolarSense:工业数据工程的智能底座
SolarSense不是一个简单的标注工具,而是一个全栈式数据工程平台。它可以对接DCS、MES、SCADA等工业系统,完成多源异构数据的统一接入、智能清洗、特征提取和标准化处理。
在工业时序数据标注场景中,SolarSense可以识别数据中的异常波动、工况切换等事件,将连续的时间序列数据拆分成一个个独立的标注任务,大大降低了专家的工作负担。
2. QApex:专家资源的高效运营平台
QApex是国内首个行业专家数据资源运营平台。我们在平台上汇聚了来自石油化工、医疗、教育、军工等多个领域的数千名资深专家,建立了完善的专家分级、任务匹配、质量管控和激励机制。
在某大型石化催化裂化工艺标注项目中,我们通过QApex平台精准匹配了石油大学专家团队(5名博士+1名教授),构建5000+小时的专家级标注,打造了高质量催化裂化工艺时序数据集。
3. 核心技术突破,时序-自然语言交叉嵌入
当前,VLA技术路线受到了产业界和学术界的广泛关注,围绕新一代工业VLA模型的数据需求,我们创建了"时序数据+自然语言描述"的交叉嵌入标注法,将专家对工艺机理、故障原因、因果链条的分析,转化为模型可识别的文本标签。
这种标注方法能够解决工业大模型的"黑盒问题"。现在,模型不仅能"看到"温度、压力等参数的变化,还能"理解"背后的工业逻辑,输出的预测结果包含完整的自然语言解释,真正满足了工业生产对安全性和可解释性的要求。
4. 国家标准制定者
作为数据标注行业唯一以第一起草单位、第一起草人主导国家数据标准的企业,景联文科技参与制定了15项国家标准,其中4份高质量数据集技术文件入选国家试点典型。

未来已来:数据标注将成为AI时代的核心基础设施
第三次革命才刚刚开始,但它的影响已经开始显现。
在石油化工行业,基于专家标注数据集训练的大模型,已经能够提前预测设备故障,极大降低误报率;在医疗行业,专家标注的医学影像数据,让AI辅助诊断的准确率超过了年轻医生;在军工行业,我们的专家标注数据,正在支撑新一代国防装备的智能化升级。
数据标注从来都不是AI的边角料,而是AI的灵魂工程师。没有高质量的行业数据,再强大的大模型也只是空中楼阁。未来,谁能掌握知识密集型标注的核心能力,谁就能成为AI时代的"卖水人",分享人工智能产业的万亿红利。 |
景联文科技已经做好了准备。我们将继续引领数据标注行业的第三次革命,打造全球领先的高质量数据生产运营商,为中国工业智能化转型提供最坚实的数据基础设施。
当AI开始改变世界,我们正在改变AI本身。





总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼
北京分公司
北京市海淀区光耀东方广场1幢9层902室
重庆基地
重庆市两江新区卉竹路2号互联网产业园2期11号楼5楼
贵阳基地
贵州省贵阳市云岩区中建大厦36楼

微信公众号

客户咨询微信
CopyRight ©️ 2026 杭州景联文科技有限公司 All Right Reserved.