

















总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼
2026具身智能数据生成四大技术路线:谁能破解「数据匮乏」死局?
具身智能被公认为人工智能走向三维物理世界的终极形态,但当前阻碍其实现跨越式发展的最大瓶颈,既不是算力架构也不是基础算法,而是极度严峻的训练数据匮乏问题。
与NLP和CV领域可通过爬虫获取海量静态数据不同,具身智能需要处理视觉、触觉、听觉、本体感受等跨模态高维输入,且数据必须具备严格的物理真实性与时序一致性。
据行业测算,训练一个具备通用物理交互能力的具身基础模型,至少需要10亿小时级别的真实世界交互数据,而目前全球累计可用的高质量具身数据不足千万小时。

面对这一行业死局,全球科研机构与科技企业正在探索四条截然不同但相互交织的技术路线。本文基于《具身智能训练数据匮乏困境的系统性破局之道》深度报告,客观拆解四大路线的核心原理、技术进展、优劣势与适用场景,为行业提供清晰的技术决策参考。
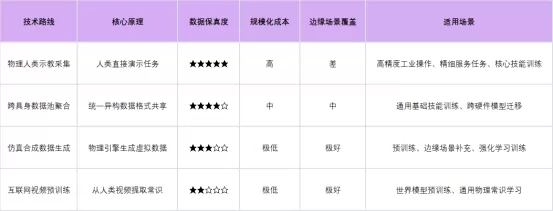
一、物理人类示教采集:保真度最高的「黄金数据」来源
核心原理:由人类专家通过亲身操作或遥操作设备,直接演示物理交互任务,记录完整的动作轨迹、力觉反馈与环境感知数据。这是目前唯一能提供100%物理真实性数据的路线,也是所有其他路线的基础。
代表技术与进展
近年来,一系列低成本硬件创新彻底打破了传统遥操作设备动辄数十万美元的成本壁垒:
• Mobile ALOHA:斯坦福大学与DeepMind联合开发的全身协同遥操作系统,总成本控制在3.2万美元左右。仅需50次示教即可让机器人完成呼叫电梯、擦拭红酒等任务,成功率达95%;即使是75秒的复杂烹饪任务,20次示教也能实现40%的自主成功率。
• GELLO/U-Arm:基于3D打印技术的运动学同构控制器,GELLO单套成本约300美元,后续演进的U-Arm更是将成本压低至50美元。通过操作与目标机械臂结构完全一致的缩小版模型,普通人也能完成高精度的关节空间控制,彻底规避了VR或鼠标操作的运动学奇异点问题。
• Open-TeleVision:依托Apple Vision Pro等消费级VR头显实现的沉浸式遥操作方案。操作者的头部、手腕与手指姿态实时映射到机器人本体,同时接收机器人第一视角3D视觉流,营造出"心智传输"般的沉浸感,特别适合人形机器人的长序列精细操作。
• Gen DAS Dex:工业级全模态手部采集设备,采用仿生外骨骼结构覆盖人手23个自由度,可同步记录姿态、力觉与触觉数据。配合头部视角设备形成"头+手"感知动作闭环,无需基站即可实现"穿戴即采",数据采集效率较传统方案提升百倍。
优劣势分析
• 优势:物理保真度最高,数据可直接映射到机器人本体;包含人类内隐的物理常识与容错反馈机制;适合高精度、接触丰富型任务。
• 劣势:边际成本随数据量线性上升;规模化扩张受人力与场地限制;难以覆盖极端危险或罕见的边缘场景。
二、跨具身数据池聚合:打破硬件孤岛的「数据共享革命」
核心原理:将不同实验室、不同机器人形态采集的异构数据进行标准化处理,构建统一的跨具身数据集,让模型能够从多种硬件的经验中学习通用物理规律。这一路线的核心目标是打造机器人领域的"ImageNet生态"。
代表技术与进展
• Open X-Embodiment:Google DeepMind主导的全球最大真实机器人开源数据集,集结了21个国际研究机构、34个实验室的力量,整合了60个独立数据集,包含超过100万条真实机器人轨迹,横跨22种机器人形态,演示了527种基本技能。其核心创新是采用RLDS统一数据格式,将所有异构动作对齐到7维标准动作空间(3维平移+3维旋转+1维夹爪状态),实现了跨硬件的数据互通。基于该数据集训练的RT-2-X模型,零样本迁移到未见过的机器人上执行新任务的成功率,可达专属数据训练模型的85%以上。
• ARIO标准:由鹏城实验室等十余家产学研机构推出的新一代具身数据标准,在Open X-Embodiment基础上进一步支持RGBD图像、3D点云与触觉模态。数据集包含300万个完整交互回合,覆盖32万多个任务实例,采用"物理采集+仿真生成+旧数据重生"三管齐下的策略,实现了历史数据资产的最大化利用。
优劣势分析
• 优势:数据规模呈指数级增长;模型可学习到通用物理规律而非单一硬件特性;大幅降低单个企业的数据获取成本。
• 劣势:不同来源的数据质量参差不齐;标准统一难度大;缺乏高价值垂直场景的深度数据。
三、仿真合成数据生成:用算力换数据的「虚拟试炼场」
核心原理:构建高度拟真的数字孪生环境,利用强化学习算法让智能体在虚拟世界中进行千万次低成本试错,生成海量合成数据。这一路线理论上可以无限生成数据,被视为解决数据匮乏的终极方案。
代表技术与进展
Genesis平台是当前最具革命性的生成式物理引擎,专为具身智能从底层重构:
• 极致物理仿真能力:同时支持刚体动力学与MPM肌肉求解器,可高精度模拟软体机器人与混合动力学系统的复杂形变。
• 恐怖算力效率:通过GPU深度优化与自动休眠机制,在基础场景下的解算帧率高达4300万FPS,虚拟时间比现实快43万倍,几小时内即可遍历海量长序列交互组合。
• VLM驱动生成:用户只需输入自然语言提示,系统即可自动生成物理规则严密的4D动态世界,包括复杂3D场景、可交互物体与人类动作序列。
• Sim2Real突破:通过极端密集的域随机化(扰动物体质量、摩擦系数、光照甚至重力常数),让模型在仿真中经历远超现实的环境方差。基于Genesis训练的四足机器狗策略,无需任何真实数据微调即可在现实中完成单双重后空翻等高难度动作。
优劣势分析
• 优势:数据生成成本极低、速度极快;可覆盖所有边缘场景与危险场景;数据标注完全自动且零错误。
• 劣势:存在"现实鸿沟",仿真环境与真实世界的物理差异可能导致模型部署后性能崩塌;复杂接触与软体变形的仿真精度仍有待提升。
四、互联网视频预训练:挖掘沉睡的「世界常识宝库」
核心原理:从互联网上数以百亿计的人类第一视角视频中提取结构化物理常识,训练视频驱动的世界模型,让机器人通过"观看"人类行为学习物理交互规律。这一路线正在引发具身智能领域的范式转移。
代表技术与进展
• H2R数据增强引擎:北京大学与华盛顿大学联合开发的自动化流水线,可将人类视频转化为机器人可用的训练数据。通过3D手部重建、运动重定向与像素级背景修复,将Ego4D等人类数据集"洗刷"为机器人视角的伪真实数据。实验证明,该方案可使真实机器人的操作成功率提升最高23.3%。
• 1X World Model(1XWM):1X科技部署在NEO人形机器人上的世界模型,采用"未来场景生成→反推执行轨迹"的双塔架构。140亿参数的主干网络先通过900小时人类第一视角视频学习基础物理常识,仅需70小时特定机器人数据微调即可适应硬件特性。
• NVIDIA DreamGen:真正实现零样本能力涌现的革命性方案。仅需一项基础抓取技能的人类示教数据,即可通过视频模型生成海量"神经轨迹",让机器人无师自通掌握关闭微波炉、熨烫衬衫等22种全新技能,并能平滑迁移到10个陌生环境中,零样本任务成功率达38.3%。
优劣势分析
• 优势:数据量近乎无限;可学习到人类的通用行为模式与常识;成本极低。
• 劣势:缺乏精确的动作标注与力觉数据;难以直接映射到机器人控制空间;复杂操作的解算精度不足。
四大技术路线对比与未来趋势
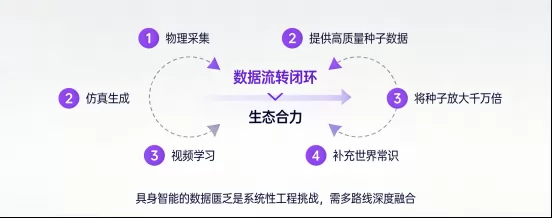
核心结论:没有任何一条单一技术路线能够独立解决具身智能的数据匮乏问题。"物理采集为核心+仿真与视频为补充"的融合路线是未来的必然方向。物理采集提供高质量的"种子数据",仿真与视频技术将这些种子放大千万倍,形成完整的数据生态。
景联文的实践:构建全链路融合的数据服务体系
作为全球领先的高质量数据生产运营商,景联文科技深度布局四大技术路线,重点打造以物理真实采集为核心、融合其他路线的全栈式数据解决方案:
1. 深耕物理采集核心能力:构建了行业最完善的物理采集体系,可7天组建1000人级标准化采集团队,覆盖居家、酒店、商超、办公室、工厂5大真实场景,掌握6大全类型采集技术。通过严格的三级审核质量管控体系,实现单批次数据合格率≥95%,为客户提供最高保真度的"黄金数据"。
2. 支持跨具身数据标准化:作为15项国家数据标准的主导或参与制定单位,景联文可按照Open X-Embodiment与ARIO标准对异构数据进行统一处理,帮助客户实现跨硬件的数据资产整合与复用。
3. 仿真数据验证与增强:与主流仿真平台合作,提供仿真数据的真实性验证服务,并利用物理采集数据对仿真模型进行校准,有效缩小"现实鸿沟"。
4. 视频数据标注与解算:拥有专业的视频标注团队,可对人类第一视角视频进行手部关键点、动作序列与物体状态的精细标注,为世界模型训练提供高质量标注数据。
结语
具身智能的数据匮乏不是一个单点问题,而是一个系统性的工程挑战。四大技术路线各有所长,也各有局限,只有通过深度融合才能形成合力。
未来,谁能够构建最完善的"物理-仿真-视频"数据流转闭环,谁就能在具身智能的竞争中占据先机。景联文科技将持续投入技术研发,不断完善全链路数据服务能力,为全球具身智能企业提供源源不断的高质量数据燃料,助力人工智能真正走进物理世界。





总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼
北京分公司
北京市海淀区光耀东方广场1幢9层902室
重庆基地
重庆市两江新区卉竹路2号互联网产业园2期11号楼5楼
贵阳基地
贵州省贵阳市云岩区中建大厦36楼

微信公众号

客户咨询微信
CopyRight ©️ 2026 杭州景联文科技有限公司 All Right Reserved.