
















总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼


80% of time to develop an AI is spent on labeling and preparing the data.

免费咨询顾问 Free

我们为数据基建到数据运营提供全链路服务
形成数据飞轮,赋能产业良性循环



数据采集标注

提供多场景自动/人工数据采集能力,覆盖文本、图像、音频、视频等全模态数据源,基于智能语料工程平台实现全流程数据处理,涵盖清洗、标注、增强、质检等环节,输出高质量结构化训练语料。
提供多场景自动/人工数据采集能力,覆盖文本、图像、音频、视频等全模态数据源,基于智能语料工程平台实现全流程数据处理,涵盖清洗、标注、增强、质检等环节,输出高质量结构化训练语料。
AI数据集
基于海量数据积累与行业洞察,我们推出标准化、高质量、即买即用的AI训练数据集,产品基于真实业务场景,经过专业采集与精准标注
基于海量数据积累与行业洞察,我们推出标准化、高质量、即买即用的AI训练数据集,产品基于真实业务场景,经过专业采集与精准标注
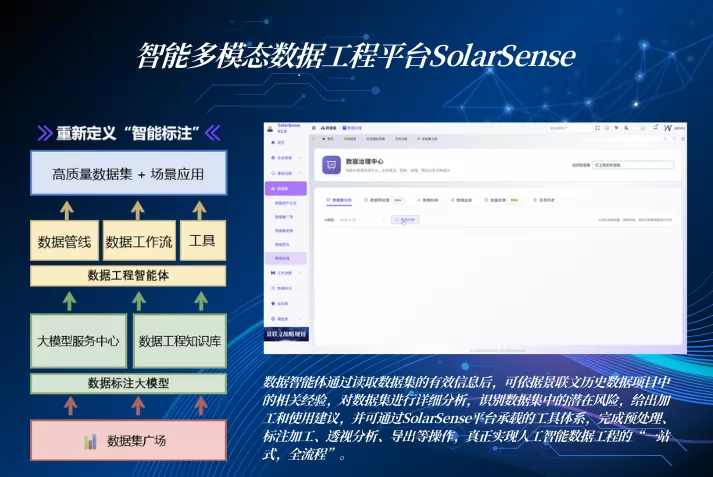
SolarSense语料工程平台
SolarSense 语料工程平台面向多源异构数据的全生命周期管理与运营场景,构建从数据采集、治理、标注、质检、增强到编目运营的全流程语料工程体系,致力于解决政务、医疗、教育、金融具身智能等领域在数据资产化过程中的标准不统一、质量不可控、价值难转化等核心问题。
SolarSense 语料工程平台面向多源异构数据的全生命周期管理与运营场景,构建从数据采集、治理、标注、质检、增强到编目运营的全流程语料工程体系,致力于解决政务、医疗、教育、金融具身智能等领域在数据资产化过程中的标准不统一、质量不可控、价值难转化等核心问题。
专家标注平台
智能化专家级数据采集系统QApex,联动专家级数据和人才源有效筛选数据,通过专家标注和专家评审,打造行业高质量数据集。
智能化专家级数据采集系统QApex,联动专家级数据和人才源有效筛选数据,通过专家标注和专家评审,打造行业高质量数据集。

景联文科技已服务1000+客户,涵盖政府、国内主流大模型公司、头部AI厂商、AI研究机构













































总部地址
杭州市滨江区西兴街道中国数谷3号楼16楼
北京分公司
北京市海淀区光耀东方广场1幢9层902室
重庆基地
重庆市两江新区卉竹路2号互联网产业园2期11号楼5楼
贵阳基地
贵州省贵阳市云岩区中建大厦36楼

微信公众号

客户咨询微信
CopyRight ©️ 2026 杭州景联文科技有限公司 All Right Reserved.