19157628936
lx@jinglianwen.com
时间:2023-09-27 15:00:38

作者:景联文科技

浏览: 次
ChatGPT的成功很大程度上归功于其采用的新的训练范式——人类反馈强化学习(RLHF)。RLHF是一种强化学习方法,它将强化学习与人类反馈相结合,通过利用人类提供的反馈来指导智能系统的行为,使其能够更加高效、快速地学习任务。
在ChatGPT的训练中,人类反馈被纳入模型的学习过程中。ChatGPT首先通过大规模的文本数据集进行预训练,然后通过与人类的交互进行微调。在这个过程中,人类用户的反馈被用来优化模型的输出,使得模型能够更好地理解人类意图,并生成更符合人类预期的文本。
这种训练范式的采用,使得ChatGPT在处理自然语言任务时表现得更为出色,如对话生成、文本摘要、语义理解等。同时,由于它可以学习人类的偏好和习惯,ChatGPT生成的文本也更符合人类的语言习惯和逻辑。

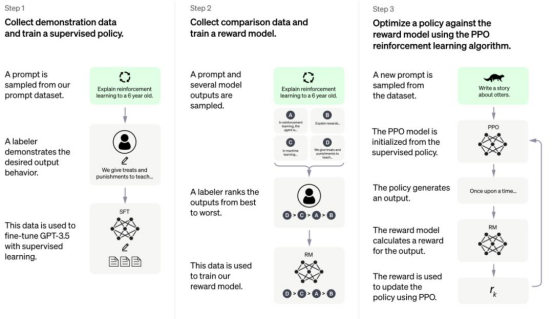
RLHF的训练过程可以分解为以下三个核心步骤:
Step1:预训练语言模型
此阶段中,模型使用常规的监督学习方法,从大量有标签的数据中学习。这一阶段的目标是让模型能够尽可能准确地理解和生成文本。
Step2:收集数据并训练奖励模型
在这一阶段,模型会生成一些文本,然后从人类那里获得反馈。这些反馈可以是关于文本的某些特定属性的评级,或者是对文本的修改建议。这个阶段的目的是让模型逐渐学会生成符合人类期望和要求的文本。
Step3:利用强化学习微调语言模型
模型使用强化学习算法来优化其生成文本的方式。这一阶段中,模型会不断地生成文本,并从人类提供者那里获得反馈(这被称为奖励)。模型的目标是最大化从这些奖励中获得的总回报。这一阶段的目标是让模型能够根据人类提供者的反馈和奖励来调整其生成文本的方式,从而尽可能地提高其生成文本的质量。
如何优化RLHF?
RLHF主要通过以下两种方式进行优化迭代:
迭代优化策略:RLHF采用迭代优化策略来提高大模型的性能。它首先使用预训练模型进行初始化,然后反复迭代训练和微调过程。在每次迭代中,它使用微调后的模型来生成新的标签,并使用这些新的标签来更新模型的权重。这个过程不断重复,直到模型性能达到满意的水平。
上下文信息:RLHF通过利用上下文信息来优化大模型的性能。它通过引入上下文信息来增强模型的表达能力和泛化能力。具体来说,它可以使用外部知识库或上下文信息来丰富输入数据,例如,在文本分类任务中,它可以整合文章之外的背景知识来提高模型对文本的理解能力。
数据是AI大模型的关键因素之一,它决定了模型的准确性、健壮性、创造性和公平性。因此,在AI领域,拥有高质量、大规模的数据集是推动AI大模型发展并取得成功的关键因素之一。
景联文标注平台支持GPT相关标注业务,具备成熟的标注、审核、质检机制,完全能够满足针对大型语言模型训练的标注需求 。
景联文科技研究人员利用GPT模型进行半自动化的数据采集和标注,用工具进行预先标注,准确率可达97%,再由人工干预进入修改,提高标注效率,以减轻人工标注者处理复杂结构化数据所需的时间和专业知识负担,用最快的速度交付高质量数据。
景联文科技提供的产品为全链条AI数据服务,从数据采集、清洗、标注、到驻场的全流程、垂直领域数据解决方案一站式AI数据服务,满足了不用应用场景下的各类数据采集标注业务的需要,协助人工智能企业解决整个人工智能链条中数据采集标注环节的相对应问题,推动人工智能在更多地场景下实现落地应用,构建完整的AI数据生态。

景联文科技|数据采集|数据标注
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
